Automatic grading of computer programs
Published at KDD 2016 [link], Blog post [link]
Work done with Varun Aggarwal and Shashank Srikant.
We pose the grading of computer programs as a machine learning problem. We extract an array of semantic features by a combination of parsing abstract syntax trees and applying NLP techniques. Using these features, we learn a supervised model to predict the grade of a response in terms of logic (functional correctness), stylistics (code clarity, structure, etc) and runtime efficiency. However, this requires us to learn a separate model for each programming question which is time-consuming and cost intensive. As part of our KDD 2016 work, we devise a semi-supervised approach to learn a single question-independent model. The basic idea is to use closeness to a set of good responses as a question-invariant feature. In doing so, we devise a novel way of scaling machine learning for open-response grading, applicable to many other domains like mathematical equations and electronic circuit solving. The utility of this research is validated by its use in hiring thousands of programmers worldwide by Aspiring Minds high-end clientele like Amazon and Baidu.
A bayesian approach to visual question answering
Course project - Probablistic Programming
Work done with Saeid Naderiparizi and Setareh Cohan.
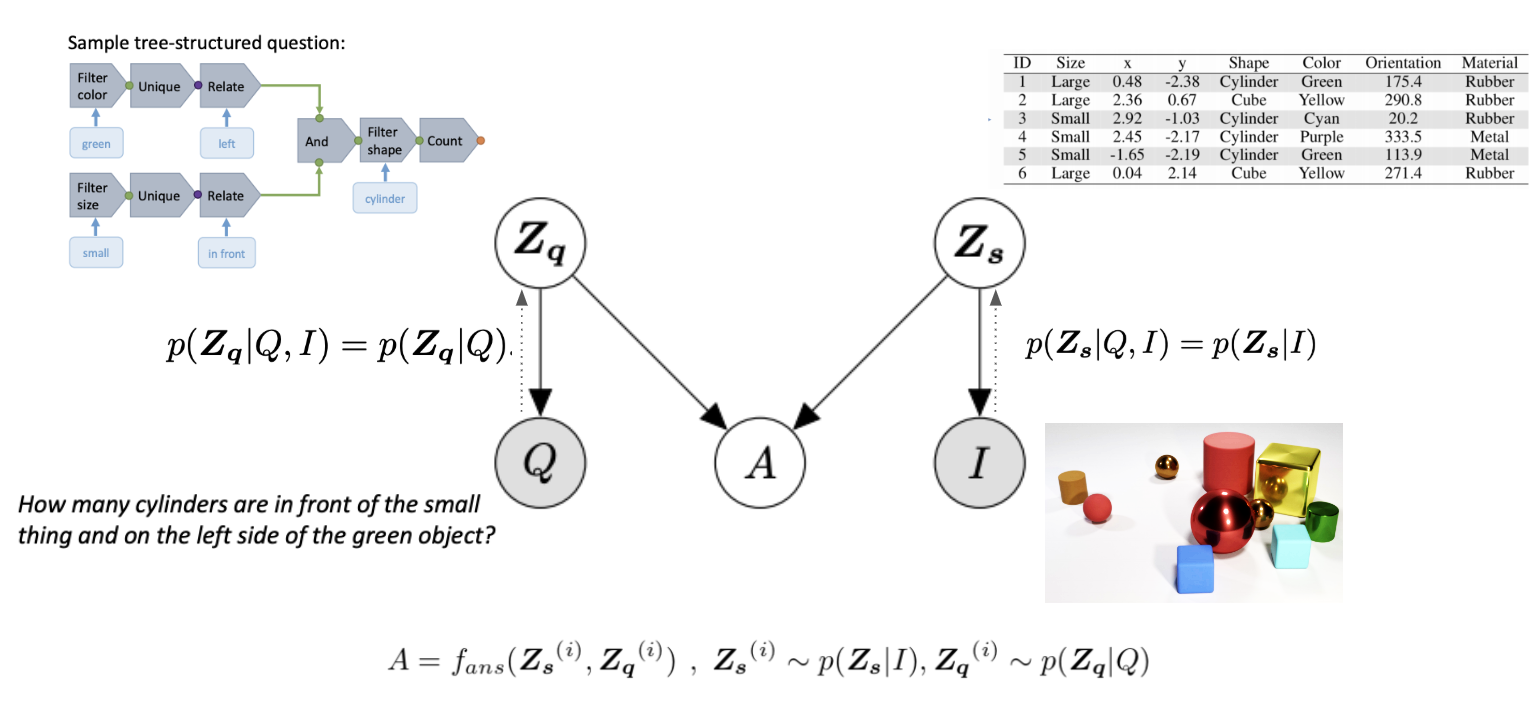
Visual question answering (VQA) is a complex task involving perception and reasoning. Typical approaches which use black-box neural networks, do well on perception but fail to generalize due to lack of compositional reasoning ability. We set up a VQA task in a fully Bayesian setting, and treat question latents, scene representation and the answer as discrete latent variables. Bayesian setup and discrete treatment of latents allow us to disentangle perception from reasoning and split the VQA task into two separate discrete-latent variable inference problems. We solve the perception using neural networks and use symbolic reasoning to arrive at an answer. We use the best of both worlds guided by the intuition that VQA task is much easier in the discrete latent space. However, discrete latents makes the optimization problem hard due to non-differentiability. We use black-box variational inference and inference compilation to perform inference on the image and show that BBVI and reinforce trick struggles due to high-variance and high dimensionality of the latent space. We show the application of our approach on the sort-of-CLEVR dataset and achieve state of the art performance. [link]
Enhanced Visual Dialog
Course project - Multimodal Learning with Vision, Language and Sound
Work done with Mohit Bajaj and Siddhesh Khandelwal.
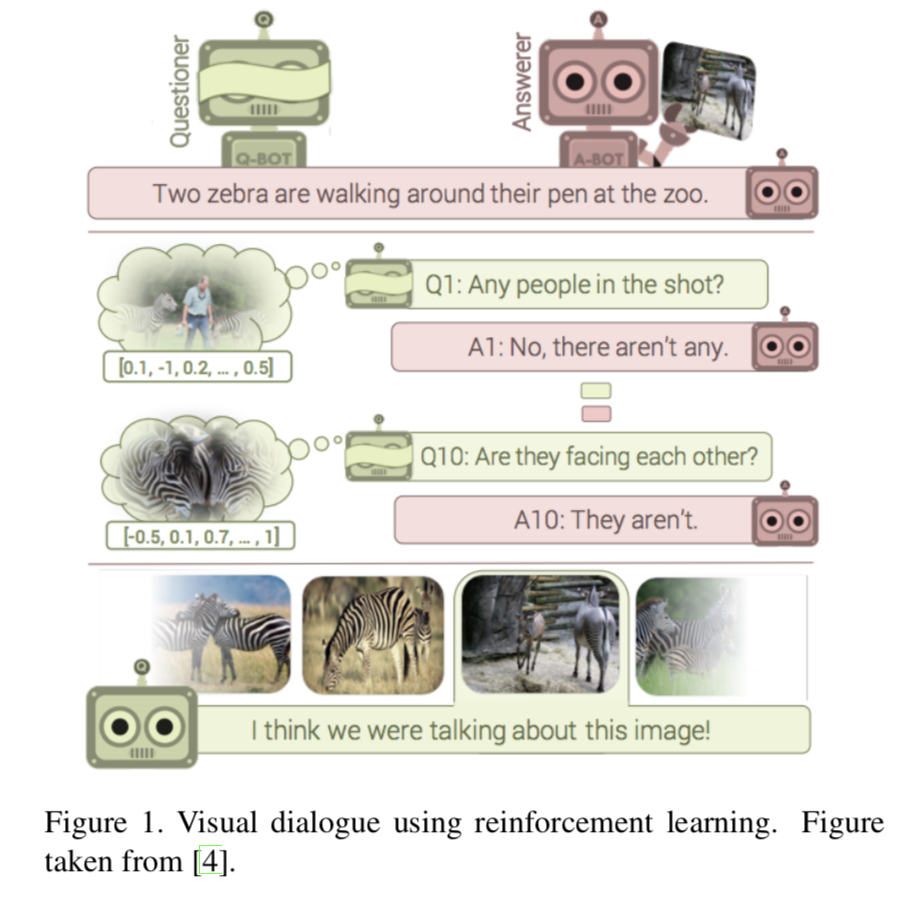
The visual dialog is the task of training an AI agent to hold meaningful dialog on images. A previous approach posed it as a deep reinforcement learning problem in which two bots - Q-Bot, the question bot, and A-bot, the answer bot, played a cooperative image guessing game. In order for the two bots to succeed the Q-Bot has to learn to ask relevant questions and A-bot has to learn to answer the questions correctly. We propose various techniques to improve performance. First, we propose a novel dynamic layer prediction mechanism that, given a question, generates a convolution filter to extract question-specific information from the image. Second, to help reduce the redundancy in the generated questions and also improve the quality of the generated answers, we propose an attention memory to keep track of past dialog information. Third, we devise a new framework that enables end-to-end training of the two bots using Gumbel-softmax approximation. Finally, we explore the use of Generative Adversarial Networks (GANs) to make the dialogue more natural and human-like. Read the full report [link]
Visualizing the bias-variance tradeoff
Course project - Information Visualization
Work done with Halldor Thorhallsson
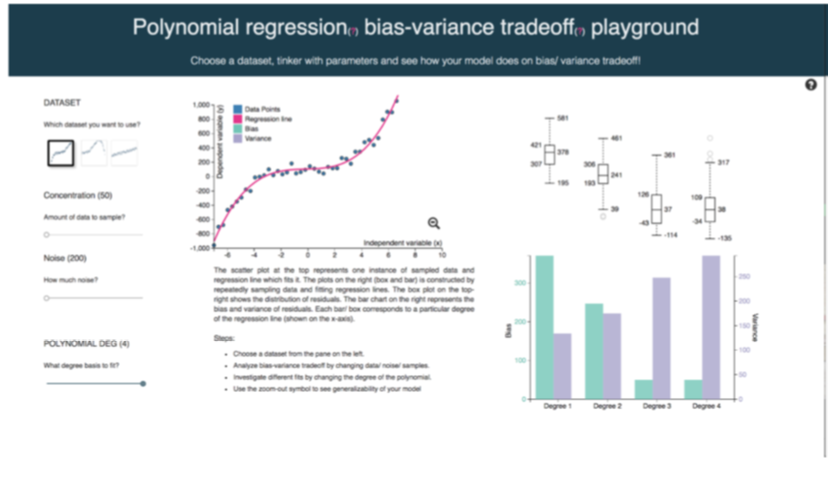
We developed a visualization tool to help obtain an intuitive understanding of the Bias-Variance tradeoff. We demonstrate two machine learning algorithms namely, Polynomial Regression, and K-Nearest Neighbours, to cover both classification and regression tasks. In our tool, users are allowed to choose the complexity of data and play with the various hyperparameters of algorithms. A change in the complexity of data and hyperparameters of models automatically update all visualizations, hence giving an intuitive understanding of the bias-variance tradeoff. Both the Polynomial Regression [link] and k-Nearest Neighbours [link] playgrounds are available online. Read the full report [link]